Radio Automatic Speech Recognition¶
Description¶
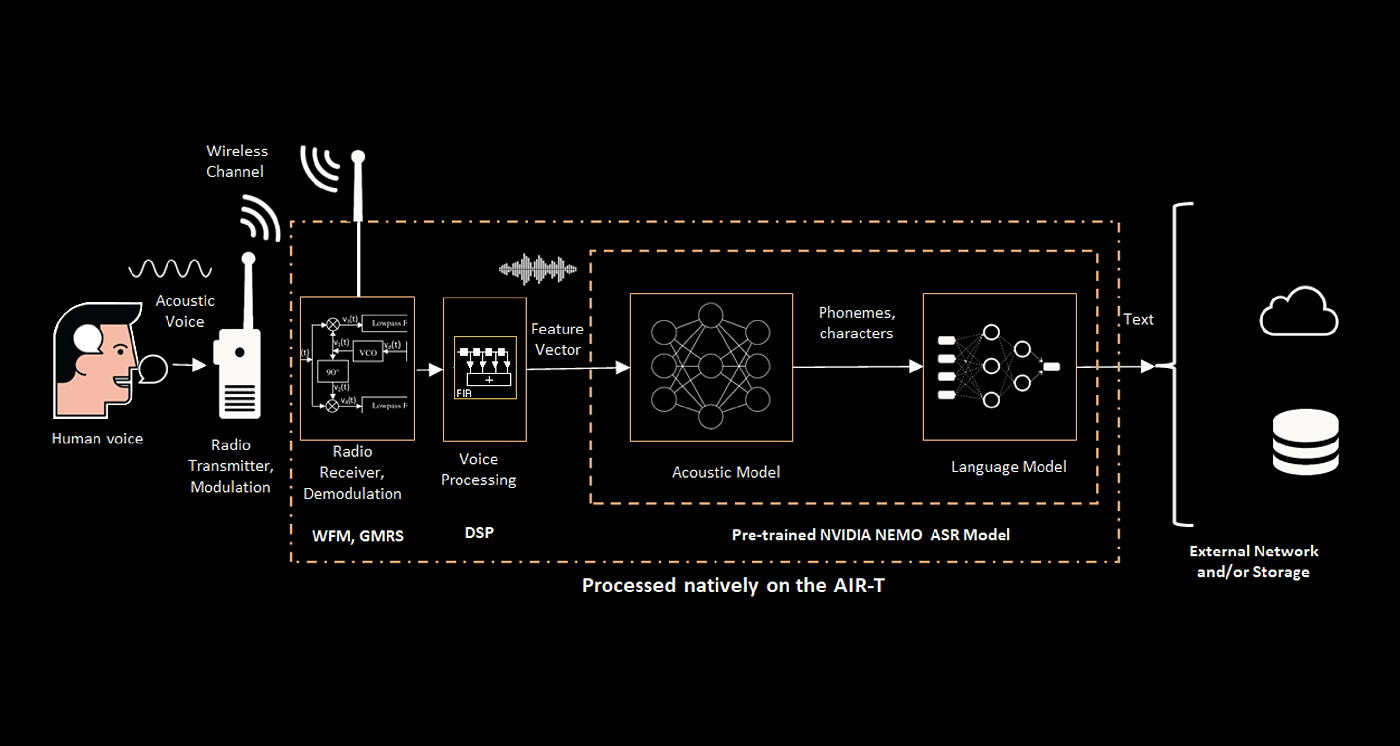
In the Deepwave Radio-ASR system, a software implementation of a narrowband FM demodulator is integrated with pre-trained speech-to-text neural network software to convert speech received over the radio into a text output. This text output can be stored locally or delivered across a minimal capacity network for further processing or analysis.
The FM demodulator works with the General Mobile Radio Service signal standard to obtain the voice signal. Demodulated voice is fed to a speech-to-text application based on the NVIDIA NeMo™ framework. NeMo™ is a toolkit for building and training natural language processing applications that uses a modular approach to speech processing. This allows users to integrate separate functions as needed for their application.
The Deepwave Radio-ASR system is completely modular. Individual components can be exchanged or customized, for example, by incorporating other demodulation schemes, or language models for languages other than English. This application highlights the key benefits of GPU integration into SDR: the ability to easily leverage pre-trained AI models for a multitude of applications.
| Information | |
|---|---|
| Date: | Oct 21, 2021 |
| Slides: | radio-asr-webinar.pdf |
| Video: | Radio ASR Webinar |
Topics¶
- Overview of automatic speech recognition (ASR)
- FM demodulation using GNU Radio
- Deep Learning with NVIDIA NeMoTM
- Demonstration of intercepting hand-held radio and performing ASR