Triton Inference Server on AIR-T¶
This tutorial will walk you through how to set up and run the triton inference server on your AIR-T and provide a minimal example to load a model and get a prediction.
Triton Inference Server is an open source inference serving software that streamlines AI inference, i.e., running an AI application for production. Triton enables teams to deploy any AI model from multiple deep learning and machine learning frameworks, including TensorRT, TensorFlow, PyTorch, ONNX, OpenVINO, Python, RAPIDS FIL, and more. Further instructions for setup and optimization can be found here: Nvidia Triton Documentation
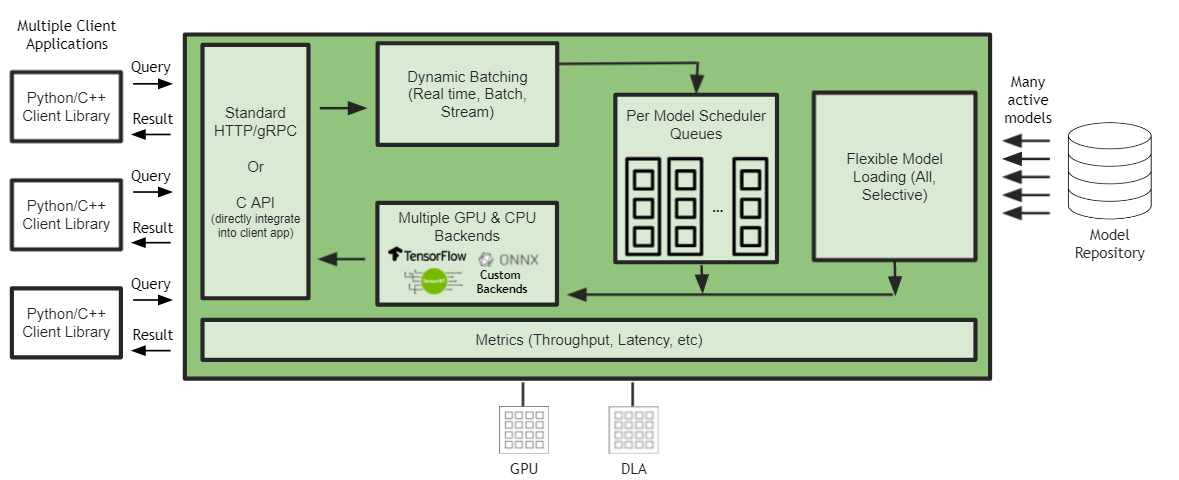
Triton Installation¶
To install triton from your AIR-T terminal:
-
Update package lists and install necessary packages:
sudo apt-get update sudo apt-get install -y --no-install-recommends \ software-properties-common \ libb64-dev \ libre2-dev \ libssl-dev \ libboost-dev \ libcurl4-openssl-dev \ rapidjson-dev \ patchelf \ zlib1g-dev \ g++-8 \ clang-8 \ lld-8 -
Download Triton Server
wget https://github.com/triton-inference-server/server/releases/download/v2.19.0/tritonserver2.19.0-jetpack4.6.1.tgz -
Upgrade pip and install PyTorch
pip3 install --upgrade https://developer.download.nvidia.com/compute/redist/jp/v461/pytorch/torch-1.11.0a0+17540c5+nv22.01-cp36-cp36m-linux_aarch64.whl -
Add LLVM to LD_LIBRARY_PATH
export LD_LIBRARY_PATH="$LD_LIBRARY_PATH:/usr/lib/llvm-8/lib" -
Extract Triton Server
mkdir /opt/triton/ tar -xvf tritonserver2.19.0-jetpack4.6.1.tgz -C /opt/triton/ cd /opt/triton/bin chmod +x tritonserver
Setup a Model Repository¶
-
Choose a folder on your AIR-T to hold your triton inference models. Inside this folder you will need to follow this format:
<model-repository-path>/ <model-name>/ [config.pbtxt] [<output-labels-file> ...] <version>/ <model-definition-file> <version>/ <model-definition-file> ... ...
We will download the model from the Inference on AIR-T tutorial and use it to request a prediction:
-
Create model directory
mkdir triton_models cd triton_models -
Create directories
mkdir avg_power_net mkdir avg_power_net/0 -
Download model onnx file into version folder
cd avg_power_net/0 wget https://github.com/deepwavedigital/airstack-examples/raw/master/inference/pytorch/avg_pow_net.onnx -O model.onnx -
Create the config.pbtxt file show below. This file should live in the top level of this model directory and be named config.pbtxt
name: "avg_power_net" platform: "onnxruntime_onnx" max_batch_size: 1 input [ { name: "input_buffer" data_type: TYPE_FP32 dims: [4096] }] output [{ name: "output_buffer" data_type: TYPE_FP32 dims: [1] }]
Note: More information on model repository setup can be found here model repository documentation
Run the Triton Server¶
If everything is installed correctly you should be able to start the triton server using:
/opt/triton/bin/tritonserver --model-repository {your model repository} --backend-directory /opt/triton/backends
Your triton inference server is now available at the listed addresses. You should be able to check the average power net model using:
curl http://0.0.0.0:8000/v2/models/avg_power_net
and receive back:
{
"name": "avg_power_net",
"versions": ["0"],
"platform": "onnxruntime_onnx",
"inputs": [
{
"name": "input_buffer",
"datatype": "FP32",
"shape": [-1, 4096]
}
],
"outputs": [
{
"name": "output_buffer",
"datatype": "FP32",
"shape": [-1, 1]
}
]
}
To request an inference result using python you can follow the code below:
import requests
import numpy as np
# Setup POST Request
url = "http://localhost:8000/v2/models/avg_power_net/infer"
headers = {'content-type': 'application/json', 'Accept-Charset': 'UTF-8'}
session = requests.Session()
# Create input data array
input_data = np.random.uniform(-1, 1, 4096).astype(np.float32)
data = (
{
"inputs": [{
"name": "input_buffer",
"shape": [1, 4096],
"datatype": "FP32",
"data": input_data.tolist()
}],
"outputs": [{
"name": "output_buffer"
}]
}
)
# Post request
r = session.post(url, json=data, headers=headers)
# Read Results
print(r.content)
For more information on HTTP/REST & GRPC protocols check out: Triton Protocols